Abstract: This paper proposes deep neural networks (DNNs) over distributed computing hierarchies, consisting of the cloud, the edge and end devices. Although a deep neural network (DNN) can accommodate inference in the cloud, a distributed deep neural network (DDNN) supported by scalable distributed computing hierarchy is advantageous. For a DNNN can scale up in neural network size as well as scale out in geographical span and it allows fast and localized inference using shallow portions of the neural network at the edge and end devices. In implementing a DDNN, we map sections of a DNN onto a distributed computing hierarchy.
Keywords: Edge Computing; Internet of Things; Neural Networks.
Introduction
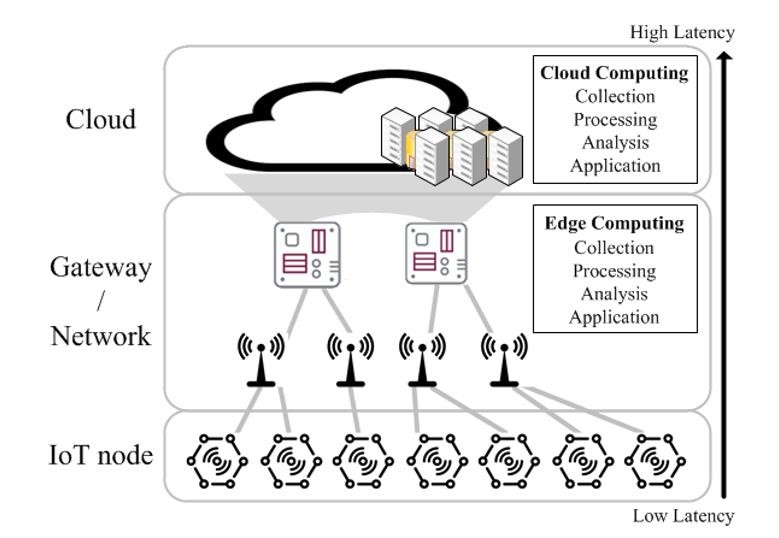
The framework of a large-scale distributed computing hierarchy has assumed new significance in the emerging era of IoT. It is widely expected that most of data generated by the massive number of IoT devices must be processed locally at the devices or at the edge, for otherwise the total amount of sensor data for a centralized cloud would overwhelm the communication network bandwidth. To this end, the goal of this project is to explore the development of heterogeneous mobile edge computing platform (Figure 1) that performs real-time Big Data analytics and deep learning with low-latency computing at the network edge.
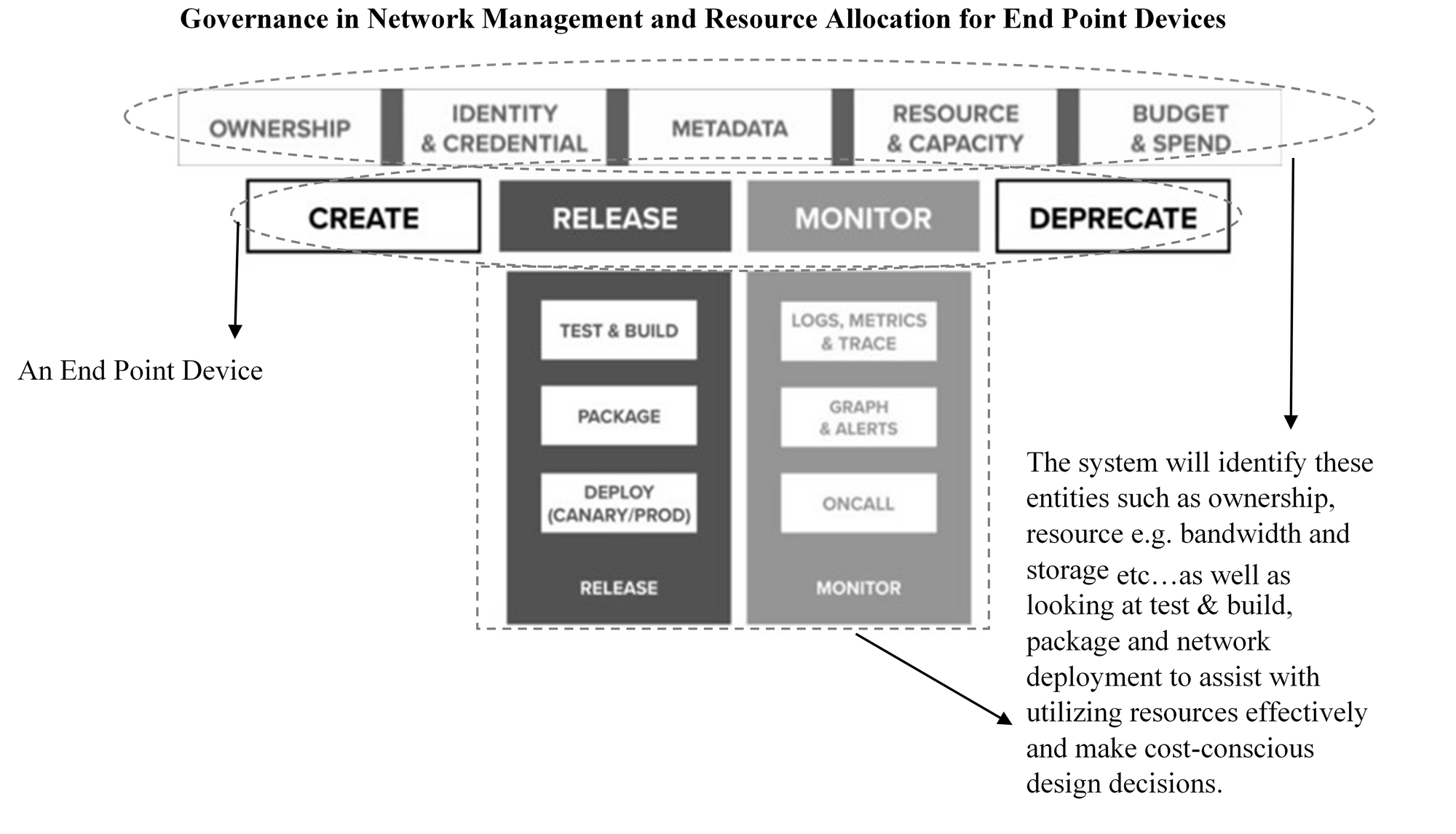
With the rise in Big Data, Cloud Computing, and the emergence of IoT Services, it is becoming essential to collate, process, manipulate data at the network edge to assist with intelligent re-orchestration. Moreover, key technologies for the creation of autonomous vehicles, smart homes and healthcare will be powered by thousands of IoT sensors and end devices, but questions such as: – What does it take to create and manage a new end point devices? (compute and storage resources) How do you identify an end service canonically across infrastructure and platform services? (identity e.g. scalability) How do you allocate resources for an end device? (resource provisioning e.g. bandwidth) What does it take to operate an end device? (monitoring e.g. dependability) How do you measure resource utilization and cost of operating an end device? (metering and chargeback e.g. energy efficiency) These questions persist regardless of an organization’s IoT strategy. Managing autonomous and intelligent re-orchestration end device (i.e., creating them, provisioning resources, deploying, metering, charging, and deprecating) at scale proves to be challenging in addressing these questions.
The rise in Internet of Things (IoT) devices as well as a dramatic increase in the number of end devices provides appealing opportunities for machine learning applications at the network edge as they are often directly connected to sensors (e.g., cameras, microphones, gyroscopes) that capture a large quantity of input data. However, the current approaches to machine learning systems on end devices are either to offload input sensory data to DNNs in the cloud, with the associated privacy concerns, latency and communication issues or perform Figure 1. Overview of Mobile Edge Computing Platform A Generic Framework for Distributed Deep Neural Networks over the Cloud, the Edge and End Devices directly on the end device using simple Machine Learning (ML) models leading to reduced system accuracy. The use of hierarchically distributed computing structures consisted of the cloud, the edge and end devices addresses these shortcomings by providing system scalability for large-scale intelligent tasks in distributed IoT and end devices which supports coordinated central and local decisions.
To this end, in implementing a DDNN, we map sections of a single DNN onto a distributed computing hierarchy and by jointly training these sections, the DDNNs can effectively address some of the challenges mentioned before. Moreover, via distributed computing, DDNNs enhance sensor fusion, data privacy and system fault tolerance for DNN applications. As a proof of concept, we show a DDNN can exploit geographical diversity of end point devices. The contributions envisaged are:
1. Literature review of existing methods for data-driven adaptation of end devices and requirements analysis of the needs at scale.
2. A generic DDNN framework and its implementation that maps sections of a DNN onto a distributed computing hierarchy.
3. A joint training method that minimizes communication and resource usage for devices and maximizes usefulness of extracted features which are utilized in the cloud, while allowing low-latency classification via early exit for a high percentage of input samples.
4. A mobile application to extensively test DDNN framework for orchestration and reorchestration of end point devices at scale.
5. A microservices architecture that implements governance at scale.
Materials and Methods
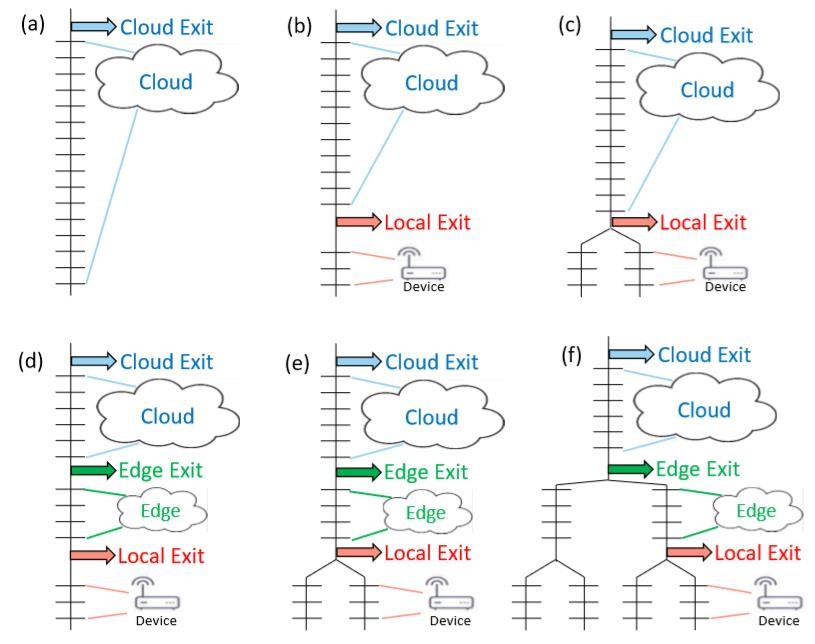
One approach is the combination of small neural network (NN) model on end devices and a larger NN model in the cloud. The small NN model on the end device performs initial feature extraction and classification if confident or otherwise the end device can draw on the large NN model in the cloud. However, this approach comes with certain challenges such limited memory and battery life one end devices such as sensors as well as multiple models at the cloud, edge and end device need to be learnt jointly which may incur huge communication costs in coordinated decision making. To address these concerns under the same optimization framework, it is desirable that a system could train a single end-to-end model, such as a DNN, and partition it between end devices and the cloud, to provide a simpler and more principled approach. DDNN maps a trained DNN onto heterogeneous physical devices distributed locally, at the edge, and in the cloud. Since DDNN relies on a jointly trained DNN framework at all parts in the neural network, for both training and inference, many of the difficult engineering decisions are greatly simplified. Figure 2 provides an overview of the DDNN architecture. The configurations presented show how DDNN can scale the inference computation across different physical devices. The cloud based DDNN in (a) can be viewed as the standard DNN running in the cloud as described in the introduction. In this case, sensor input captured on end devices is sent to the cloud in original format (raw input format), where all layers of DNN inference is performed.
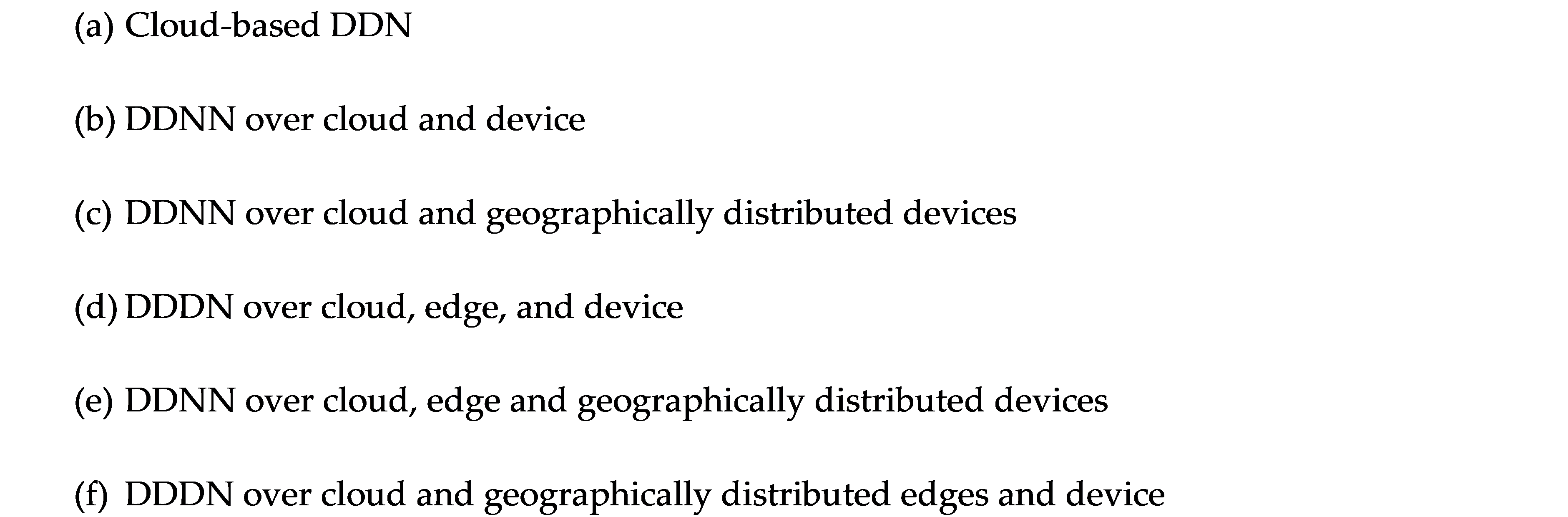
Results
Through DDNNs, we undertook design and development of visual gesture recognizer using Raspberry Pi (x19), Neural Compute Stick (x5), Nvidia Jetson TX1 (x2), Microsoft Kinect V2, associated machine vision, and the CUDA and Tensor Flow deep-learning framework. In this work, computer vision libraries are used together to design and develop a real-time visually and contextually intelligent gesture recognizer.
In machine learning approaches, the developer first creates a training set consisting of videos of people performing the gesture. The developer then labels the videos with which frames and which portions of the depth or RGB data in the frame correspond to the gesture’s movements. Finally, the developer runs an existing machine learning algorithm, such as AdaBoost, to synthesize gesture recognition code that can be included in a program. The developer takes recordings of many different people performing the same gesture, then tags the recordings to provide labeled data. From the labeled data, the developer synthesizes a classifier for the gesture. The classifier runs as a library in the application. Machine learning approaches have important benefits compared to manually written poses. If the training set contains a diverse group of users, such as users of different sizes and ages, the machine learning algorithm can “automatically” discover how to detect the gesture for different users without manual tweaking.
With the rise of sensors such as the Microsoft Kinect, Leap Motion, and hand motion sensors in phones such as the Samsung Galaxy S5, natural user interface (NUI) has become practical. NUI raises two key challenges for the developer: first, developers must create new code to recognize new gestures, which is a time-consuming process. Second, to recognize these gestures, applications must have access to depth and video of the user, raising privacy problems. We address both problems with Prepose, a novel domain-specific language (DSL) for easily building gesture recognizers, combined with a system architecture that protects user privacy against untrusted applications by running Prepose code in a trusted core, and only interacting with applications via gesture events. Prepose lowers the cost of developing new gesture recognizers by exposing a range of primitives to developers that can capture many different gestures. Further, Prepose is designed to enable static analysis using SMT solvers, allowing the system to check security and privacy properties before running a gesture recognizer. We demonstrate that Prepose is expressive by creating novel gesture recognizers for 28 gestures in three representative domains: physical therapy, tai-chi, and ballet. We further show that matching user motions against Prepose gestures is efficient, by measuring on traces obtained from Microsoft Kinect runs. Because of the privacy-sensitive nature of always on Kinect sensors, we have designed the Prepose language to be analyzable: we enable security and privacy assurance through precise static analysis. In Prepose, we employ a sound static analysis that uses an SMT solver (Z3), something that works well on Prepose but would be hardly possible for a general-purpose language. We demonstrate that static analysis of Prepose code is efficient and investigate how analysis time scales with the complexity of gestures. Our Z3-based approach scales well in practice: safety checking is under 0.5 seconds per gesture; average validity checking time is only 188 ms; lastly, for 97% of the cases, the conflict detection time is below 5 seconds, with only one query taking longer than 15 seconds.

{kind=link}